The proposed architecture was tested with different real-world data sets. The number of input attributes was between eight and 12000.
Throughout the experiment it appeared that the modular network converged for a large range of network parameters. Particularly for huge input spaces it was often very difficult to find an appropriate learning coefficient for a monolithic network, whereas convergence was no problem for the modular structure.
The time needed to train the modular network was much shorter than that for a monolithic network. In most cases it took less than half the time to train the network to a similar performance. For larger input spaces the training was up to ten times quicker (without parallel training).
For small input spaces (up to 60 attributes) the memorization and generalization performance of the modular network and a monolithic MLP were very similar on the real-world data sets.
One task was to memorize five pictures of different faces. Each gray-level pictures had a size of 75 by 90 pixels (6750 continuous input variables). The original pictures are from [5]. After training the generalization performance was tested with distorted pictures. In Figure 5 one training picture (upper left) and some degenerations of this picture are shown.

Figure 5: Original and Distorted Pictures.

Figure 6: Examples of Noisy Test Pictures.
The modular network had a much higher recognition rate on the manually distorted pictures.
Another comparison was made on the ability to recognize noisy inputs. The noise on the pictures was generated randomly. In Figure 6 pictures with different noise-levels are shown. The modular network could recognize pictures with a significant higher noise-level than the single MLP; the results are shown in Figure 7.
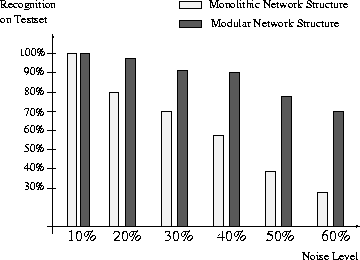
Figure 7: The Performance on Noisy Inputs.
From the above experiments it can be seen that the modular network has superior generalization abilities on high dimensional input vectors.